
Last updated on February 3rd, 2025 at 10:47 am
Amazon Bedrock provides an easy way to integrate foundation models into applications without needing to manage infrastructure. One of its most powerful features is the Knowledge Base, which, when combined with retrieval-augmented generation (RAG), enables models to generate responses grounded in real-time, relevant data. Instead of relying solely on pre-trained knowledge, RAG-based systems retrieve external information before generating responses, making AI applications much more dynamic and useful.
In this guide, I’ll walk you through the process of setting up the Amazon Bedrock Knowledge Base, configuring RAG, and optimizing it for performance and accuracy. I’ll explain the key concepts, go step by step through the setup process, and highlight best practices for tuning your system. By the end, you’ll have a fully functional knowledge base integrated with RAG.
Before we get into the setup, let’s break down what these technologies actually do and why they matter
Amazon Bedrock Knowledge Base
The Amazon Bedrock Knowledge Base is a managed retrieval system that connects generative AI models to external structured (SQL, JSON) and unstructured (PDFs, text, documents) data sources. Instead of AI models relying purely on their pre-trained knowledge, they can now fetch the latest, relevant data from connected sources before responding to a user query.
Retrieval-Augmented Generation (RAG)
RAG is a method that enhances large language models (LLMs) by dynamically retrieving relevant context from a knowledge source before generating responses. It works in two main steps:
- Retrieval: The system searches for the most relevant documents or data based on a query.
- Generation: The AI model takes that retrieved information and incorporates it into its response, improving factual accuracy.
Prerequisites
Before starting, ensure you have:
- An AWS account with access to Amazon Bedrock
- An S3 bucket for storing documents
- The necessary IAM permissions to access Bedrock and other AWS services
Now that we understand the basics, let’s go step by step through setting up the Amazon Bedrock Knowledge Base – Breaking each section of the set up page for easier understanding of why and how things are configured.
- Set Up Amazon Bedrock Knowledge Base
- Configure Data Source
- Embedding Model & Vector Store
- Verify OpenSearch Dashboard
- Test the Knowledge Base
- Monitoring and Continuous Improvement
- Conclusion
Set Up Amazon Bedrock Knowledge Base
This is the Step 1 of the entire setup process
- Log in to AWS Console → Navigate to Amazon Bedrock.
- Go to Knowledge Base and click Create Knowledge Base.
- Provide a name and description.
- Create a new IAM Service Role
- Choose the Data Source, for this tutorial I am selecting Amazon S3
- Optional – Add Tags and at the time of writing this tutorial there is option to configure log delivery to CloudWatch, S3 or Data Firehose, I am not selecting any log delivery.
Configure Data Source
In Step 2 as you can see I have to provide my S3 bucket details. In that S3 bucket I uploaded a sample a ddos_runbook pdf file.
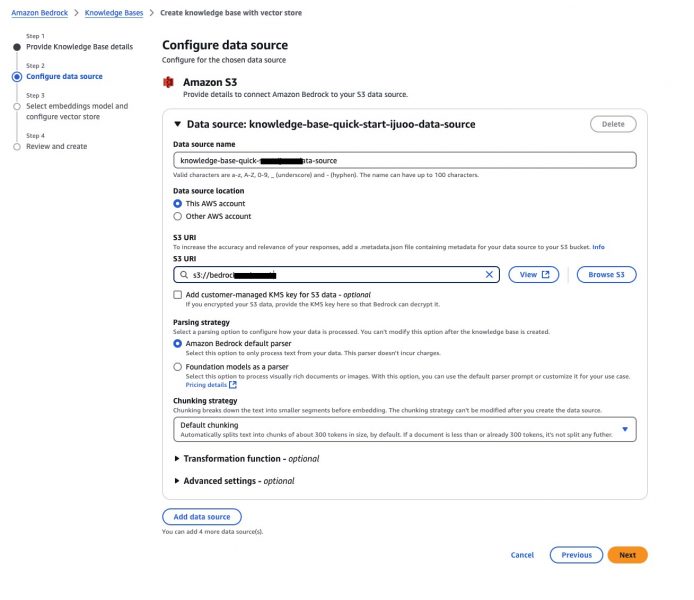
This sample pdf document covers how to mitigate DDoS Attack on a Linux Ubuntu Server, identifying mitigating strategies and installing fail2ban as the remedy thereby strengthening the security of the server.
Once your data sources are configured, the knowledge base is ready for integration into retrieval-augmented generation (RAG) pipelines.
Embedding Model & Vector Store
Step 3 of the configuration is to
- Choose an embedding model (Amazon Titan, Cohere etc.,).
- Select a Vector database (Amazon OpenSearch, Pinecone etc.,).
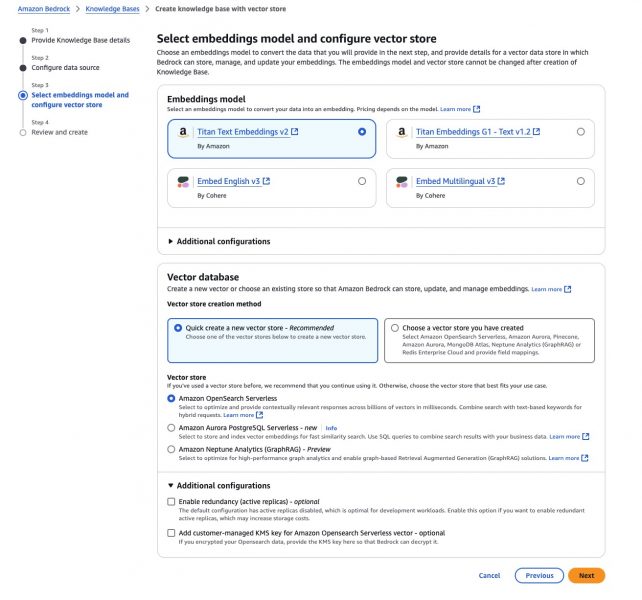
I selected Quick Create a new vector store with Amazon OpenSearch Serverless as the vector store.
Click “Next” and review all the configuration you have selected and press “Create Knowledge Base” button.
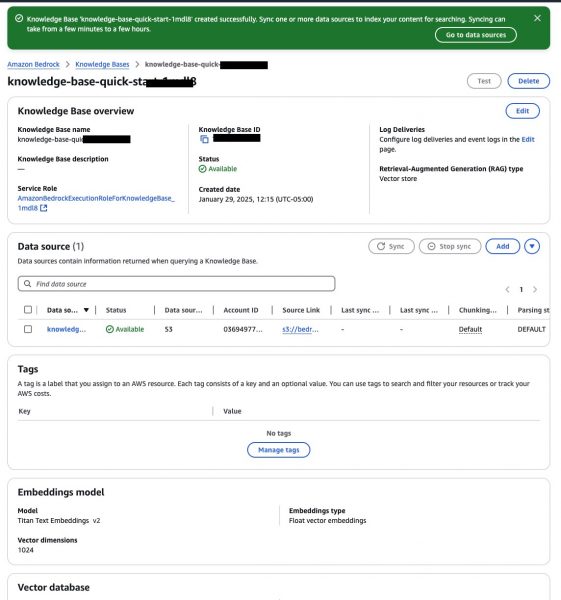
It take around 7 mins to complete.
Before we start testing the response, go inside your data source and click on sync. After the sync is completed you should see a window similar to the one below. Once done, the knowledge base will start indexing the documents you uploaded, making them searchable and retrievable.
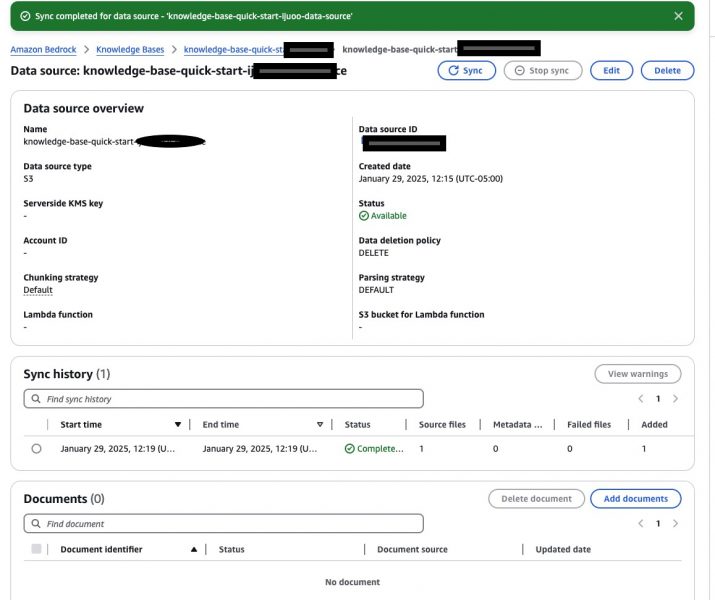
Verify OpenSearch Dashboard
After the data source sync is successful, go to your AWS OpenSearch console Serverless section and click on Collections,
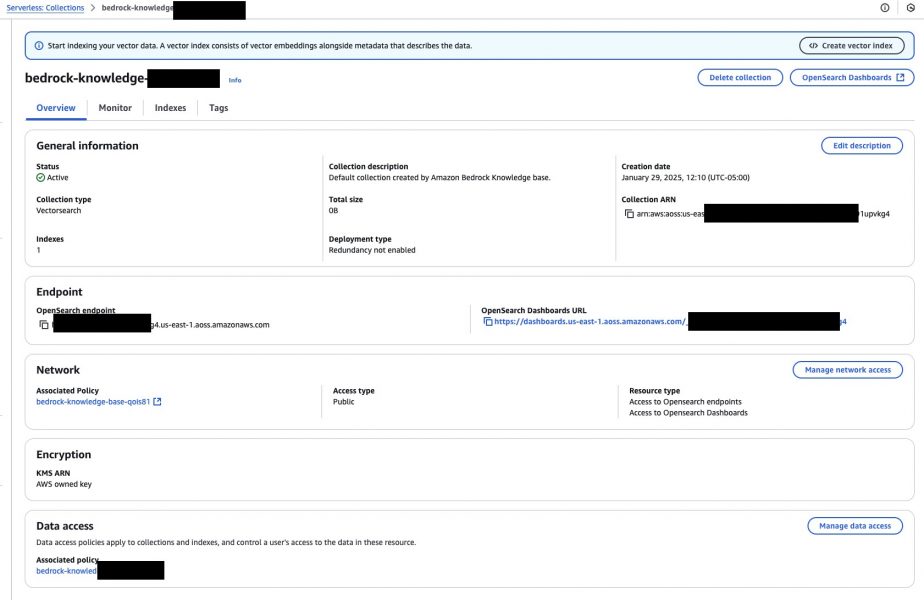
Your collection details looks like the image above. Under “Indexes” tab you will see an index name similar to bedrock-knowledge-base-default-index, keep a note of that index name. To view more details of the metadata and vector fields just click on the index.
For accessing OpenSearch console, Click on the “OpenSearch Dashboards URL” hyperlink.
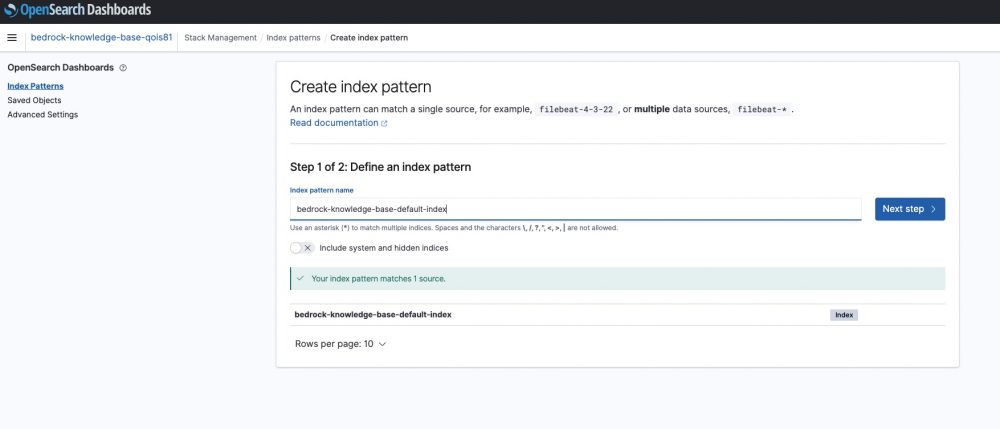
In the OpenSearch dashboard click on the left sidebar options and select Discover and since it is the first time you need to click Create Index Pattern / Provide the index name in my case “bedrock-knowledge-base-default-index“
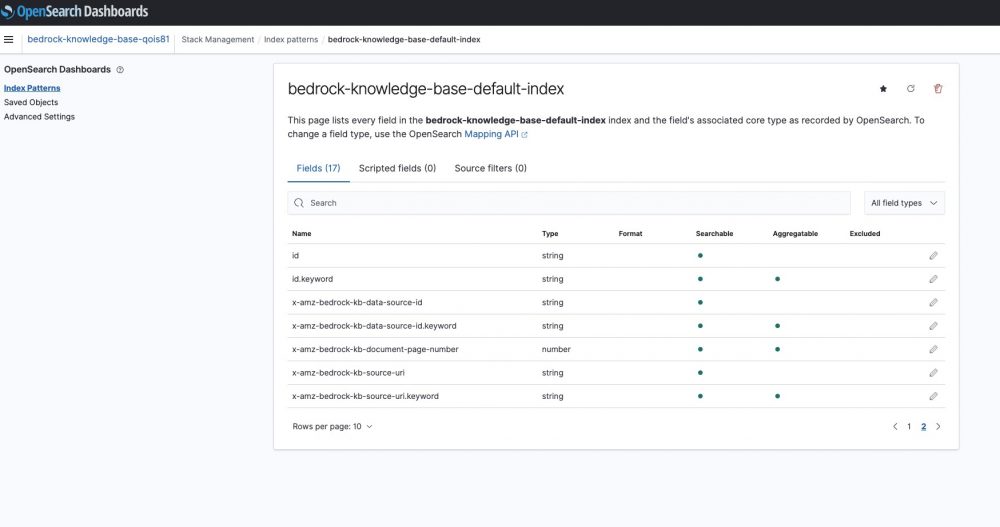
Next step is to create Index, as you can see it split my document in to chunks with field names added.
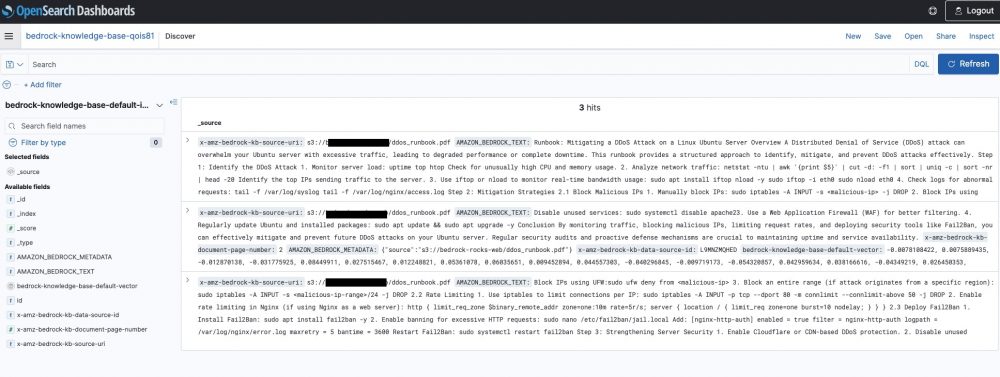
We are all set now and ready to test an end to end configured Amazon Bedrock knowledge base.
Test the Knowledge Base
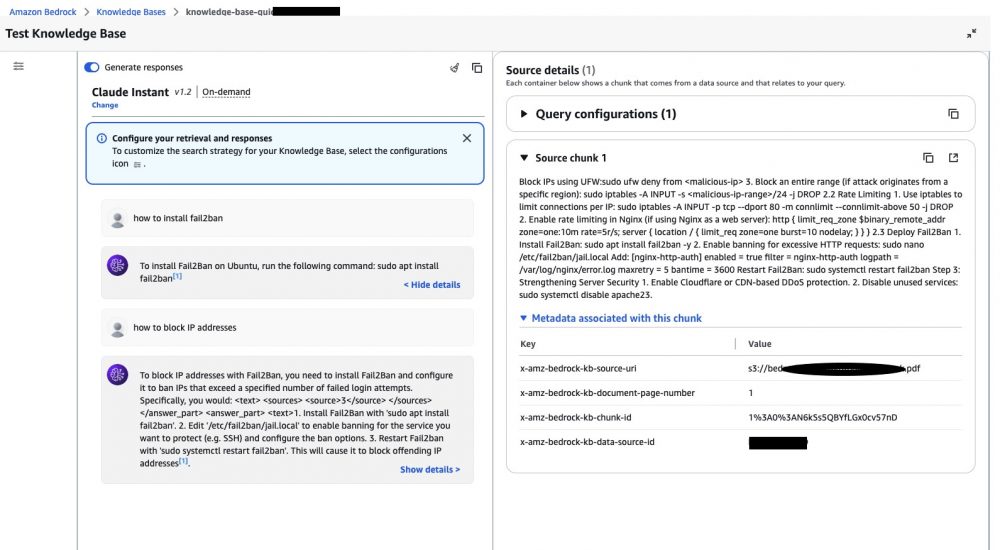
If you go inside your AWS Knowledge base section on the Amazon Bedrock console, Click on “Test” button and on the right pane you will see chat option popping up.
Select the model of your choice and start asking questions. While answering question it also shows the source from which it fetched the details.
Monitoring and Continuous Improvement
To maintain performance over time, set up real-time monitoring and feedback loops:
- Use Amazon CloudWatch for logging and tracking retrieval latency.
- Regularly update indexed documents to reflect the latest information.
- Implement user feedback mechanisms to improve ranking and relevance.
Conclusion
Pricing associated with these services we have used here are listed below. Since we are using OpenSearch keep an eye on the pricing and make sure to delete the Knowledge Base and OpenSearch collection if no longer required.
By setting up Amazon Bedrock Knowledge Base and fine-tuning RAG, you can build AI applications that deliver more accurate, context-aware, and up-to-date responses. Whether for chatbots, search engines, or internal enterprise tools, integrating RAG ensures your AI is grounded in real-world knowledge.
